
Generador de poemas usando Word Embedding, basado en la poesía de Gabriela Mistral
29 Mar 2020En términos simples el Word Embedding consiste en la transformación de palabras en vectores numéricos con los que, luego, se pueden efectuar operaciones matemáticas (como calcular la similitud, por ejemplo). Buscando algún uso entretenido a este método, se me ocurrió desarrollar un generador de poemas utilizando la obra de Gabriela Mistral.
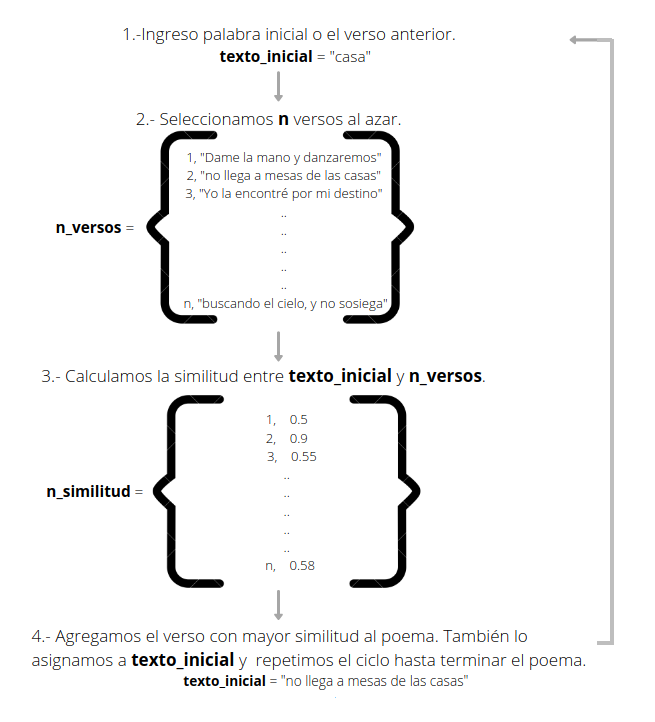
El objetivo es crear un nuevo poema a partir de una palabra inicial. Luego, selecciono algunos versos al azar y calculo la similitud con esta palabra. El verso con mayor similitud se agrega al “nuevo poema” para, posteriormente, repetir el proceso tomando este verso como texto de comparación en el siguiente ciclo, hasta completar el poema. Aquí una ilustración del proceso:
Recopilación de los poemas
Los poemas los obtuve desde el sitio web www.poemas-del-alma.com utilizando un web-scraper que escribí en Python, con el que logre recopilar 86 poemas en total, que guarde en un archivo .csv. El código es el siguiente:
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
#this trick the server to dont reject the connection
class AppURLopener(urllib.request.FancyURLopener):
version = "Mozilla/5.0"
opener = AppURLopener()
datos = opener.open('http://www.poemas-del-alma.com/gabriela-mistral.htm').read().decode()
#search and save poems links
soup = BeautifulSoup(datos, 'html.parser')
poem_list = soup.find(class_="list-poems")
links = poem_list.findAll('a')
results = ["http://www.poemas-del-alma.com/"+link.get('href') for link in links]
#saves title and content of each poem
titles = []
corpus = []
for page in results:
datos = opener.open(page).read().decode()
soup = BeautifulSoup(datos, 'html.parser')
title = soup.find(class_='title-poem')
poem = soup.find(class_='poem-entry')
titles.append(title.getText())
print(title.getText())
corpus.append(poem.find('p').getText())
#saves to a .csv file all the poems
poems = pd.DataFrame({'title' : titles,'text' : corpus})
poems.to_csv('poems.csv')
Separación y limpieza de versos
Para la separación de los versos creé una función que toma como input el archivo .csv con los poemas y una expresión regular, que se utiliza como criterio de división. En mi caso todos los versos se encuentran divididos por un salto de línea, por lo que solo tuve que ingresar eso en la función.
En relación a la limpieza, corregí algunos caracteres que se encontraban erróneos en todos los texto (signos de puntuación e interrogación en lugares equivocados, por ejemplo) también decidí eliminar los dos puntos y los puntos a parte, de manera que el poema resultante pudiera verse con mayor conexión entre los versos.
import os
import re
import pandas as pd
#function to split and clean the poems
def docs_to_sentences(file, split):
path = os.getcwd()
df_docs = pd.read_csv(path+"/" + file)
number_docs = df_docs.shape[0]
df_sentences = pd.DataFrame(columns=['doc_id','sentence'])
for i in range(number_docs):
text = df_docs.text[i]
#dictionary to replace unwanted elements
replace_dict = {'?«' : '«', '(' : '', ')' : '', ':' : ',' ,'.' : ','}
for x,y in replace_dict.items():
text = text.replace(x, y)
text = text.lower()
#split into sentences
sentences = re.split(split, text)
len_sentences = len(sentences)
doc_id = [i] * (len_sentences)
#save sentence and poem_id
doc_sentences = pd.DataFrame({'doc_id' : doc_id, 'sentence' : sentences})
df_sentences = df_sentences.append(doc_sentences)
#extra cleaning and reset index
df_sentences = df_sentences[df_sentences.sentence != '\r']
df_sentences.reset_index(drop=True, inplace=True)
return df_sentences
#saves to a .csv file all the sentences
df = docs_to_sentences(file='poems.csv', split=r"\n")
df.to_csv('sentences.csv')Generador de poemas
El generador de poemas toma el archivo .csv del paso anterior, una palabra inicial y el numero de versos como input.
Con la palabra inicial se inicia el proceso, por lo que idealmente esta debería ser un término amplio para aumentar la posibilidad de encontrar un verso con alta similitud.
El cálculo de similitud se hace con la librería spaCy, que cuenta con un modelo en español que incluye los vectores del Word Embedding.
Para realizar la selección aleatoria elegí tomar un numero de 30 frases o versos y también verifiqué que estos no fueran del mismo poema que el verso anterior. El código es el siguiente:
import pandas as pd
import numpy as np
import spacy
# load Spacy model
nlp = spacy.load("es_core_news_md")
#function to generate poem
def poem_generator(file, word, n_sents=4):
#transform initial word to a Spacy Doc object
init_str = nlp(word)
sentences = pd.read_csv(path+'/'+ file)
sup_index= sentences.shape[0]
poem_id = int()
poem =[]
#generate the sentences
for i in range(n_sents):
rand_sent_index = np.random.randint(0, sup_index, size=(30))
sent_list = list(sentences.sentence.iloc[rand_sent_index])
#transform sentences to a Spacy Doc object
docs = nlp.pipe(sent_list)
#compute similarity for each sentence
sim_list = []
for sent in docs:
similarity = (init_str.similarity(sent))
sim_list.append(similarity)
#saves similarity to DataFrame
df_1 = pd.DataFrame({'similarity' : sim_list, 'doc_id' : sentences.doc_id.iloc[rand_sent_index] }, index=rand_sent_index)
df_1 = df_1[df_1.doc_id != poem_id]
df_1.sort_values(by='similarity', inplace=True, ascending=False)
sent_index= df_1.index[0]
sent = sentences.sentence[sent_index]
#erase line jump and carriage return
replace_dict = {'\n' : '', '\r' : ''}
for x,y in replace_dict.items():
sent = sent.replace(x, y)
#saves sentence to poem list
poem.append(sent)
poem_id = df_1.doc_id.iloc[0]
init_str = nlp(sent)
#join the sentences with a line break
str_poem = ("\n".join(poem))
return str_poem
#generate a poem with initial word ='sueño'
poem = poem_generator(file='sentences.csv',word='sueño')Formato del poema
Para darle un mejor formato al poema resultante pase mayúscula la primera palabra y también agregue un punto al final.
#function add format to the poem
def format_poem(text):
text = text[:1].upper() + text[1:]
text = text[:-1] + '.'
return text
#print the poem with new format
final_poem = format_poem(poem)
print(final_poem)Resultados
Yo elegí generar poemas con 4 versos, para disminuir la posibilitad de que estos no tuvieran sentido.
Estos son algunos de los resultados que a mi más me gustaron:
- Poema “sueño”

- Poema “amor”

- Poema “hambre”

En general, los poemas son bien entretenidos y aunque en algunos casos el resultado final no es muy coherente, en la mayoría de las veces pasa desapercibido cómo se crearon.
Interesante, ¿no?