
Detección de tópicos en los los discursos de Piñera, utilizando NMF y LDA
06 Mar 2020El modelado de tópicos es una técnica de machine-learning que nos permite encontrar los temas o tópicos existentes dentro de un conjunto de textos. A pesar de que en la web existen diversos ejemplos de esta técnica, en general, es difícil encontrar alguno en español o que no sea un análisis de una base de datos de tuits. Por lo anterior, me pareció interesante aplicar Latent Dirichlet Allocation (LDA) y Non-negative Matrix Factorization (NMF) a los discursos de Sebastián Piñera desde el 18 de octubre y ver la eficacia de estas técnicas en este tipo de corpus (o conjunto de texto) menos extenso.
Recopilación de datos
Los textos los obtuve desde las transcripciones automáticas de Youtube, en los vídeos de los discursos. También elegí seleccionar solo los vídeos provenientes de los canales de televisión abierta y con una duración mínima de 3 minutos, para así evitar las “cuñas” y solo dejar los más relevantes.
El listado utilizado es el siguiente:
Limpieza de datos
Una vez descargadas las transcripciones, es necesario limpiarlas para poder utilizarlas. De esta forma, hay que quitarles los marcadores de tiempo, pasar el texto a minúscula y remover los saltos de línea, los puntos, las comas, etc.
Para realizar esta limpieza utilicé el siguiente código en Python, que toma una transcripción texto.txt y genera un texto limpio con el nombre de texto_clean.txt
import re
import string
file = 'estado_emergencia_18_10_19.txt'
#insert the time marks for the start and finish selection
start = '06:04'
finish = '20:21'
open_folder='texts_raw/'
clean_folder='texts_cln/'
with open(open_folder+file, 'r') as f:
text_raw = f.read()
#Cut the text between the time marks
def cut_text(text,start_time, finish_time = ''):
if start_time != '00:00':
split = text.split(start_time)
part_1 = split[1]
else:
part_1 = text
if finish_time != '' :
split = part_1.split(finish_time)
part_1 = split[0]
return part_1
#Make text lowercase, remove square brackets, empty lines, etc
def clean_text(text):
text = text.lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('(\d{2,3}):(\d{2})', '', text)
text = re.sub('\s{1}\n{1}', ' ', text)
text = re.sub('[,\.]','', text)
text = re.sub('\n', ' ', text)
return text
text_clean = cut_text(text_raw, start, finish )
text_clean = clean_text(text_clean)
#save the clean text into a new file
new_file = file.split('.')[0]+ '_clean'
f= open(clean_folder+new_file,"w+")
f.write(text_clean)
f.close
print (text_clean)Lematización y remoción de stop-words
En términos simples, la lematización, consiste en el proceso de transformar una palabra al vocablo por el que la encontraríamos en un diccionario. Por ejemplo:
| Palabra original | Palabra lematizada |
|---|---|
| encontrarse | encontrar |
| peces | pez |
Elegí utilizar esta técnica porque me parece que es más comprensible que el stemming, a la hora de analizar la coherencia de un tópico o tema, dentro del texto.
Esto lo realicé con el siguiente código, que también remueve las stop-words o palabras vacías del corpus:
import os
import nltk
from nltk.corpus import stopwords
import spacy
spanish_stopwords = stopwords.words('spanish')
#empty list to load the texts
corpus = []
path = os.getcwd()
print(path)
#search in the /texts_cln folder
files = os.listdir(path+'/texts_cln')
list_files = [f for f in files if f[-5:] == 'clean']
for file in list_files:
with open('texts_cln/'+file, 'r') as f:
data = f.read()
corpus.append(data)
#lemmatize the texts and save them in a list
corpus_lemma = []
nlp = spacy.load("es_core_news_md")
allowed_postags=['NOUN', 'ADJ', 'ADV','VERB']
for doc in corpus:
text = nlp(doc)
document = []
document.append([token.lemma_ for token in text
if token.pos_ in allowed_postags])
corpus_lemma.append(" ".join(document[0]))Transformación de datos: N-grams y vectorización del corpus
En el procesamiento de lenguage natural (NLP) los n-grams son secuencias de n-palabras dentro de un texto. Utilizarlos dentro de los modelos nos puede ayudar a capturar mas significado dentro de un tópico, donde podrían existir palabras que siempre aparecen seguidas(Por ejemplo: Derechos Humanos, Fuerzas Armadas). Para este análisis decidí utilizar palabras individuales y bigrams (n=2).
Para que los textos puedan ser analizados por los modelos, se deben transformar a una Matriz de frecuencias de palabras. En esta, cada fila representa un texto y cada columna una palabra. El valor de la celda es el número de veces que aparece el token o palabra en el texto. Por ejemplo
| no | si | quiero | |
|---|---|---|---|
| texto n°1: “no quiero” | 1 | 0 | 1 |
| texto n°2: “si quiero” | 0 | 1 | 1 |
El código para la vectorización y generación de bi-grams es el siguiente:
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(max_df=0.9,
stop_words = spanish_stopwords, ngram_range=(1,2))
corpus_vect = vect.fit_transform(corpus_lemma)Latent Dirichlet allocation (LDA)
Latent Dirichlet Allocation es un modelo que supone que cada documento es una mezcla de un número de tópicos y asume que estos a priori tienen una distribución de Dirichlet. Este modelo tiene varios parámetros que se pueden ajustar, pero el más importante es el número de tópicos que uno cree que existen en el corpus. Este último se debe ingresar, ya que no está definido previamente.
Para el análisis del corpus realizaremos un barrido por los siguientes valores de números de temas o tópicos = [5,6,7], elegidos a criterio personal. Luego, observaremos si alguno de estos modelos entrega un grupo de tópicos mas coherente.
El siguiente código entrega un archivo .csv con las 6 palabras más relevantes por tópico, para cada numero de tópicos(n_topics):
import pandas as pd
import numpy as np
from sklearn.decomposition import LatentDirichletAllocation
#latent dirichlet allocation model
def LDA_model(texts,topics):
lda_model = LatentDirichletAllocation(
n_components=topics, learning_method='batch',
random_state=0, max_iter=50, learning_decay=0.9,
n_jobs = -1)
#fit the model
lda_model.fit_transform(texts)
return lda_model
#function that return the top words per topic
def show_topics(vect, lda_model, n_words):
keywords = np.array(vect.get_feature_names())
topic_keywords = []
for topic_weights in lda_model.components_:
top_keyword_locs = (-topic_weights).argsort()[:n_words]
topic_keywords.append(keywords.take(top_keyword_locs))
return topic_keywords
n_topics = [5,6,7]
#generate a .csv file with the top words per topic
for n in n_topics :
model = LDA_model(corpus_vect,topics=n)
topic_keywords = show_topics(vect=vect, lda_model=model, n_words=6)
df_topic_keywords = pd.DataFrame(topic_keywords)
name_file = 'topics_lda_'+str(n)+'_.csv'
df_topic_keywords.to_csv(name_file)Los resultados son los siguientes:
Modelo con 5 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n° 1 | aguar | mayor | seguridad | querer | orden | ciudadano |
| n° 2 | derecho | humano | derecho humano | querer | año | día |
| n° 3 | querer | acordar | violencia | día | derecho | social |
| n° 4 | mayor | salud | pensionar | familia | querer | nuevo |
| n° 5 | querer | mayor | día | ley | saber | esforzar |
Modelo con 6 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n° 1 | aguar | querer | orden | seguridad | mayor | policía |
| n° 2 | derecho | humano | derecho humano | año | querer | respetar |
| n° 3 | querer | día | escuela | aviación | forzar | sentir |
| n° 4 | pensionar | mayor | querer | vida | familia | mejorar |
| n° 5 | querer | ley | día | mayor | carabinero | saber |
| n° 6 | derecho | querer | día | nuevo | salud | mejor |
Modelo con 7 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n° 1 | mayor | querer | orden | social | seguridad | derecho |
| n° 2 | derecho | humano | querer | derecho humano | aguar | día |
| n° 3 | significar | acordar | temor | justicia | chile | violencia |
| n° 4 | vivienda | familia | riesgo | querer | agradecer | lugar |
| n° 5 | carabinero | día | empresa | ley | pyme | saber |
| n° 6 | querer | día | derecho | nuevo | cumplir | policía |
| n° 7 | mayor | pensionar | mejorar | agenda | social | adulto |
Si revisamos las 3 tablas (si sé, son hartas palabras) no parece haber un modelo claramente mejor y, aunque algunos tópicos parecen ser más coherentes, la mayoría no cumple muy bien el objetivo de encontrar los temas dentro de lo discursos.
Non-negative matrix factorization (NMF)
EL NMF consiste en la descomposición de la matriz de frecuencia de palabras (V), en 2 matrices mas pequeñas que representan los tópicos (H) y los relevancia de cada tópico en cada texto (W).
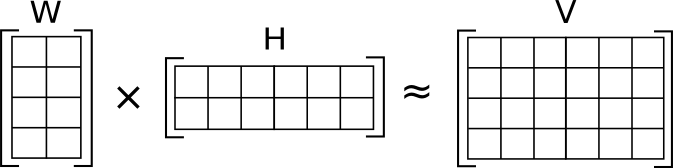
Al igual que en el modelo LDA, se deben seleccionar el numero de tópicos que uno cree existen en el grupo de textos . Para poder hacer la comparación realizaremos el mismo proceso anterior, y buscaremos el mejor modelo para un numero de tópicos igual a = [5,6,7] .
import pandas as pd
import numpy as np
from sklearn.decomposition import NMF
# Non-negative matrix factorization model
def NMF_model(texts,topics):
text = normalize(texts, norm='l1', axis=1)
NMF_model = NMF(n_components=topics, init='nndsvd');
#fit the model
NMF_model.fit(texts)
return NMF_model
#function that return the top words per topic
def show_topics(vect, lda_model, n_words):
keywords = np.array(vect.get_feature_names())
topic_keywords = []
for topic_weights in lda_model.components_:
top_keyword_locs = (-topic_weights).argsort()[:n_words]
topic_keywords.append(keywords.take(top_keyword_locs))
return topic_keywords
n_topics = [5,6,7]
#generate a .csv file with the top words per topic
for n in n_topics :
model = LDA_model(corpus_vect,topics=n)
topic_keywords = show_topics(vect=vect, lda_model=model, n_words=6)
df_topic_keywords = pd.DataFrame(topic_keywords)
name_file = 'topics_nmf_'+str(n)+'_.csv'
df_topic_keywords.to_csv(name_file)
Los resultados son los siguientes:
Modelo con 5 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n°1 | derecho | agenda | año | social | acordar | constitución |
| n°2 | humano | derecho | derecho humano | respetar | querer | personar |
| n°3 | salud | problema | esperar | medicamento | mejor | enfermedad |
| n°4 | mayor | pensionar | adulto | adulto mayor | mejorar | reformar |
| n°5 | querer | día | vida | carabinero | ley | aguar |
Modelo con 6 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n°1 | agenda | derecho | social | año | violencia | acordar |
| n°2 | humano | derecho | derecho humano | respetar | querer | siempre |
| n°3 | salud | problema | esperar | medicamento | mejor | enfermedad |
| n°4 | mayor | pensionar | adulto | adulto mayor | mejorar | reformar |
| n°5 | querer | día | vida | aguar | carabinero | ley |
| n°6 | derecho | constitución | principiar | acordar | oportunidad | político |
Modelo con 7 tópicos
| tópico | ||||||
|---|---|---|---|---|---|---|
| n°1 | agenda | derecho | social | año | acordar | violencia |
| n°2 | humano | derecho | derecho humano | respetar | querer | personar |
| n°3 | salud | problema | esperar | medicamento | mejor | enfermedad |
| n°4 | mayor | pensionar | adulto | adulto mayor | mejorar | reformar |
| n°5 | querer | día | vida | carabinero | policía | cumplir |
| n°6 | derecho | constitución | principiar | acordar | oportunidad | político |
| n°7 | aguar | querer | utilizar | mejor | enfrentar | gran |
Ahora es posible ver mayor coherencia en todos los casos, en comparación con los resultados entregados por la aplicación de LDA en 5,6 y 7 tópicos.
En particular, el NMF con 7 tópicos parece ser el más preciso en separar los distintos temas que existen en los discursos analizados. De esta manera, es más fácil comprender sobre qué tratan los discursos analizados.
¿Cuales son los temas ?
Con un modelo aceptado ( NMF de 7 tópicos) ya podemos ponerle nombre a los tópicos. Esto se hace a criterio personal y de lo que uno piensa es el tema que abarca las palabras de cada tópico. Yo los nombré de esta manera:
| tópico | Nombre |
|---|---|
| n°1 | agenda social |
| n°2 | derechos humano |
| n°3 | salud |
| n°4 | pensiones |
| n°5 | fuerza policial |
| n°6 | constitución |
| n°7 | otros |
Conclusión
Se puede observar que modelos con Non-negative matrix factorization (NMF) entregan, en general, mejores resultados que los que utilizan Latent Dirichlet allocation (LDA), considerando un corpus con un numero bajo de textos. Es probable que este ultimo necesite un mayor número de textos para poder mejorar su convergencia.
También se puede decir que la aplicación de estas técnicas a los discursos puede ser de gran utilidad para poder determinar de manera más objetiva los temas que los políticos o personas influenciadoras comunican en los medios.