
Análisis de sentimientos utilizando BERT en español
04 Aug 2020A pesar de que el análisis de sentimientos no es algo nuevo, se hace difícil encontrar ejemplos utilizando el modelo BERT en español. Por esa razón, me pareció interesante realizar este análisis y ver su comportamiento en comparación con modelos mucho más simples. Para esto último, decidí usar Naive Bayes para crear un modelo base, que servirá de referencia para evaluar los resultados.
¿Que es BERT?
BERT es un modelo de deep learning del lenguaje natural creado por Google. Si te interesa conocer su arquitectura en más detalle te recomiendo leer este post, que posee una excelente explicación.
Particularmente, para el análisis que les presento en este post, utilizaré BETO, que corresponde al modelo BERT entrenado en español por el DCC de la Universidad de Chile.
Recopilación de datos
Para comenzar el análisis busqué datos del tipo ‘review’ (que contaran con un comentario y una valorización) y me pareció que un contenido accesible eran las opiniones de usuarios en la Google Play Store. Particularmente, decidí recolectar las de la app de yapo.cl y así tener un dataset en español.

Para esto construí un scraper utilizando Selenium, que se encarga de hacer scroll para ir mostrando más opiniones, también expande los textos de estas y por último guarda el texto junto con la valorización en un archivo .csv. El código es el siguiente:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import pandas as pd
import time
#function get reviews from google apps website
def get_reviews(url):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url)
# number of scrolls to keep loading reviews
scroll_loops = 12
for a in range(scroll_loops):
driver.execute_script("window.scrollTo(
0,document.body.scrollHeight)")
time.sleep(3)
show_more = driver.find_elements(
By.XPATH, "//span[.='Mostrar más']")
print(show_more)
#if a 'show more' button exist, clicks on
if show_more:
time.sleep(2)
element = show_more[0]
actions = ActionChains(driver)
actions.move_to_element(element).perform()
show_more[0].click()
print('click')
else:
driver.execute_script("window.scrollTo(
0,document.body.scrollHeight)")
print('end of page')
time.sleep(5)
# Search and click "see full review" buttons
element = driver.find_element_by_class_name("Rc8qze")
driver.execute_script("""var element = arguments[0];
element.parentNode.removeChild(element);
""", element)
for button in WebDriverWait(driver, 10).until(
EC.visibility_of_all_elements_located(
(By.XPATH, "//button[contains(text(),
'Ver opinión completa')]"))):
button.click()
time.sleep(1)
# Collect reviews and ratings
main_div = driver.find_element_by_xpath(
'//div[@jsname="fk8dgd"]')
stars = main_div.find_elements_by_xpath(
'//div[@class="pf5lIe"]/div[1]')
reviews = main_div.find_elements_by_xpath(
'//div[@jscontroller="LVJlx"]')
stars_len = len(stars)
reviews_text = [review.text for review in reviews]
stars_text = [star.get_attribute("aria-label")
for star in stars[1:(stars_len-5)]]
# Save everything to a .csv file
df = pd.DataFrame(data={'reviews':reviews_text,
'stars':stars_text})
df.to_csv('reviews.csv')
# Call function on the 'yapo.cl' google app site
get_reviews("https://play.google.com/store/apps/details?id=cl.yapo&hl=es_GT&showAllReviews=true")Esto no das una recopilación de 1080 opiniones y que tienen la siguiente distribución:
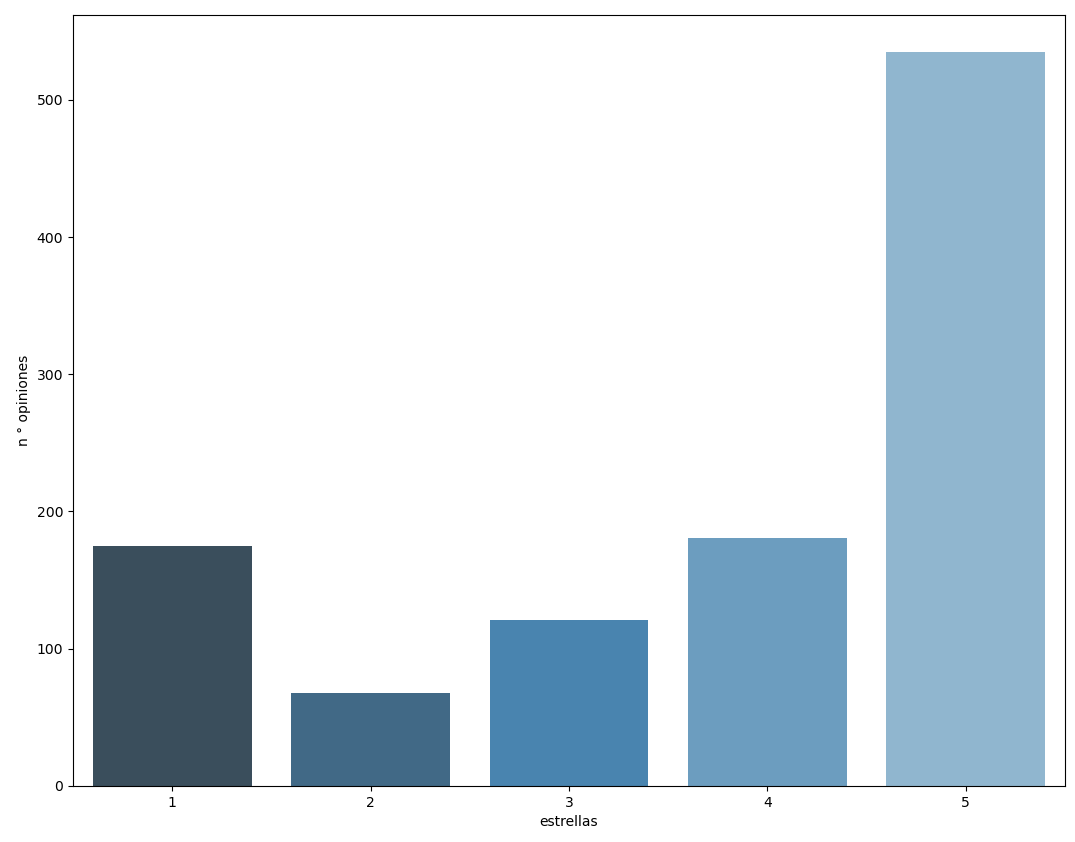
Limpieza y preparación de datos
Una vez obtenidos los datos, es necesario limpiarlos y prepararlos antes de ingresarlos a los modelos. Primero transformé las valorizaciones que se encuentra como strings (por ejemplo: “3 estrellas”) a las categorías que utilizaremos: negative, neutral y positive. Esto lo hice con la siguiente equivalencia:
- 1 o 2 estrellas: negative
- 3 estrellas : neutral
- 4 o 5 estrellas: positive
También transforme estas categorías a una codificación con valores numéricos, que es el formato que necesita el modelo con BERT. Por último, corregí palabras con errores ortográficos, eliminé las tildes (solo para el modelo Naive Bayes) y guardé todo en un archivo .csv. Aquí está el código de lo señalado:
import pandas as pd
# function to replace incorrectly spelled words
def correct_speeling(text):
replace_dict = {'tenindo': 'teniendo',
'tranferencia': 'transferencia', 'grscias':'gracias',
'cion':'ción','albañi':'albañil',
'aplicasion':'aplicación','arrglenl':'arreglenlo',
'arreglenloo':'arreglenlo','avanze':'avance',
'direccione':'direcciones','24marzo':'24 marzo',
'yapooo':'yapo','yapoo':'yapo', 'yapos':'yapo'}
for x, y in replace_dict.items():
text = text.replace(x, y)
return text
# function to clean and transform the reviews
def clean_csv(file):
df = pd.read_csv(file)
df['rating'] = df['stars'].apply(
lambda x: re.findall("[0-9]", x)[0])
df['sentiment'] = df['rating'].map(
{'1':'negative','2':'negative', '3':'neutral',
'4':'positive', '5':'positive'})
df['class'] = df['rating'].map({'1':0,'2':0, '3':1,
'4':2, '5':2})
a, b = 'áéíóúü,.:', 'aeiouu '
trans = str.maketrans(a, b)
df['clean_reviews'] = df['reviews'].apply(
lambda x: x.lower())
df['clean_reviews'] = df['clean_reviews'].apply(
correct_speeling)
df['clean_reviews_nb'] = df['clean_reviews'].apply(
lambda x: x.translate(trans))
print(df.head())
df.to_csv(file[:-4]+'clean.csv')
#call function on the previously collected reviews
clean_csv('reviews.csv')Modelo base de referencia: Naive Bayes
Para establecer una referencia de comparación cree un modelo utilizando Naive Bayes, que nos servirá para evaluar los resultados con BERT. El código busca el parámetro óptimo alpha y también utiliza validación cruzada para calcular la exactitud del modelo. Este es el código:
import pandas as pd
import re
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn.metrics import plot_confusion_matrix
#function that create and fit the naive bayes model
def naive_bayes(file):
df = pd.read_csv(file)
X_train, X_test, y_train, y_test = train_test_split(
df['clean_reviews_nb'],
df['sentiment'],
stratify =df['sentiment'],
test_size=0.2, random_state=42)
count_vect = CountVectorizer()
X_train_count = count_vect.fit_transform(X_train)
X_test_count = count_vect.transform(X_test)
param_grid = [{'alpha':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6,
0.7, 0.8, 0.9, 1]}]
mln = MultinomialNB()
clf = GridSearchCV(mln, param_grid,cv=5)
clf.fit(X_train_count, y_train)
print("optimun alpha:{}".format(
clf.best_params_['alpha']))
print("accuracy: {}".format(
clf.score(X_test_count, y_test)))
y_test_pred = clf.predict(X_test_count)
conf_matrix = plot_confusion_matrix(
clf,X_test_count, y_test,
cmap=plt.cm.summer, normalize='true')
plt.show()
#call function on the cleaned reviews
naive_bayes('reviewsclean.csv')Este modelo nos da una exactitud de 0.791 y la siguiente matriz de confusión:
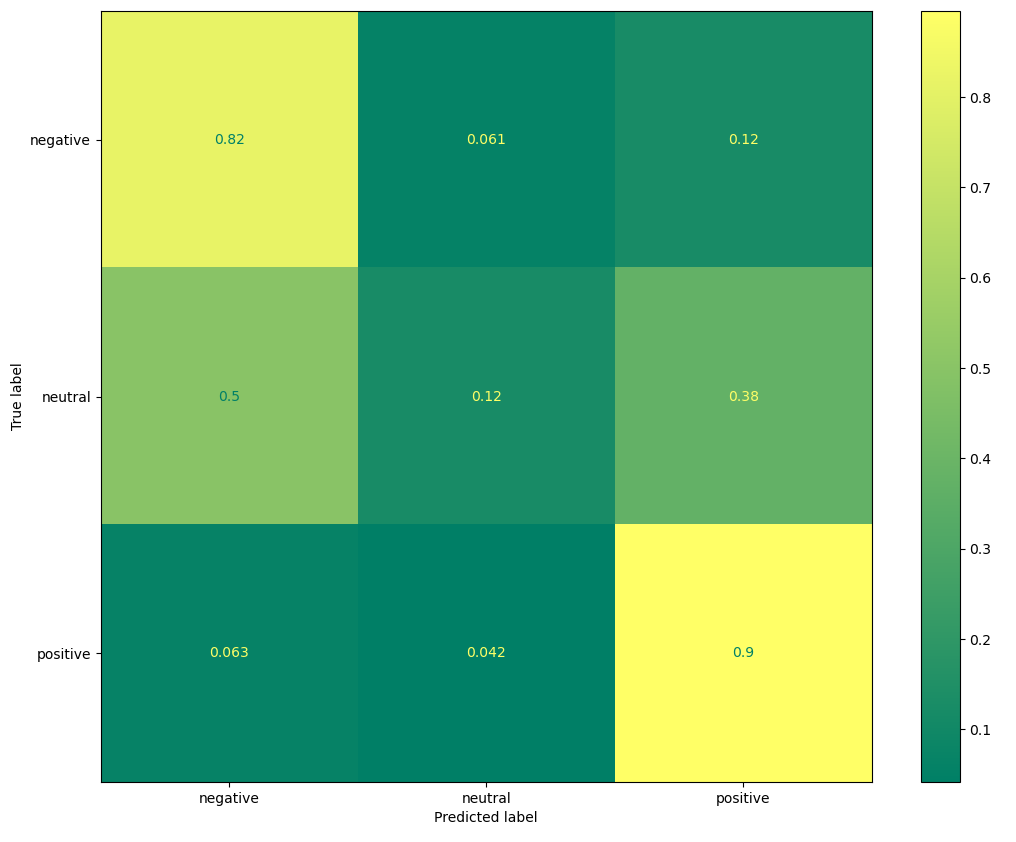
Como se observa, la exactitud del modelo no es mala pero tiene un bajo desempeño a la hora de clasificar las opiniones del tipo neutral.
Modelo utilizando BETO
El primer paso fue descargar el modelo preentrenado para PyTorch . También empleé la librería transformers de hugginfface que posee un modelo BERT predefinido para clasificación: BertForSequenceClassification. Este último no es mas que BERT con una capa de clasificación encima.
Después de cargar los datos debemos tokenizar nuestro dataset. Este paso nos generará los vectores con los tokens y la attention mask. Debemos tener cuidado de que el valor de max_length sea mayor al número mayor de tokens por review. Este es el código:
import torch
from transformers import BertTokenizer
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader, SequentialSampler
from transformers import BertForSequenceClassification, AdamW
from transformers import get_linear_schedule_with_warmup
from sklearn.model_selection import train_test_split
import torch.optim
import numpy as np
import pandas as pd
import time
import datetime
import random
from sklearn.metrics import confusion_matrix
# Select cpu or cuda
run_on = 'cpu'
device = torch.device(run_on)
# Load the dataset into a pandas dataframe.
df = pd.read_csv('/reviewsclean.csv', header=0)
reviews = df['clean_reviews']
sentiment = df['class']
# Split dataset
X_train, X_val, y_train, y_val = train_test_split(reviews,
sentiment, stratify=sentiment, test_size=0.2, random_state=42)
# Report datasets lenghts
print('Training set length : {}'.format(len(X_train)))
print('Validation set length : {}'.format(len(X_val)))
# Tokenization
tokenizer = BertTokenizer.from_pretrained("pytorch/",
do_lower_case=True)
def preprocessing(dataset):
input_ids = []
attention_mask = []
for doc in dataset:
encoded_doc = tokenizer.encode_plus(doc,
add_special_tokens=True, max_length=115,
truncation=True,pad_to_max_length=True)
input_ids.append(encoded_doc['input_ids'])
attention_mask.append(encoded_doc['attention_mask'])
return (torch.tensor(input_ids),
torch.tensor(attention_mask))
# Apply preprocessing to dataset
X_train_inputs, X_train_masks = preprocessing(X_train)
X_val_inputs, X_val_masks = preprocessing(X_val)
# Report max n° tokens in a sentence
max_len = max([torch.sum(sen) for sen in X_train_masks])
print('Max n°tokens in a sentence: {0}'.format(max_len))Luego creamos los dataloaders de PyTorch para el dataset de entrenamiento y de validación.
# Data loaders
batch_size = 32
y_train_labels = torch.tensor(y_train.values)
y_val_labels = torch.tensor(y_val.values)
def dataloader(x_inputs, x_masks, y_labels):
data = TensorDataset(x_inputs, x_masks, y_labels)
sampler = SequentialSampler(data)
dataloader = DataLoader(data, sampler=sampler,
batch_size=batch_size,
num_workers=0)
return dataloader
train_dataloader = dataloader(X_train_inputs, X_train_masks,
y_train_labels)
val_dataloader = dataloader(X_val_inputs, X_val_masks,
y_val_labels)Ahora establecemos los valores aleatorios, de manera de que nuestros resultados sean reproducibles. También cargamos el modelo, el optimizador, definimos los epochs y el scheduler en PyTorch.
# set random seed
def set_seed(value):
random.seed(value)
np.random.seed(value)
torch.manual_seed(value)
torch.cuda.manual_seed_all(value)
set_seed(42)
# Create model and optimizer
model = BertForSequenceClassification.from_pretrained(
"pytorch/", num_labels=3, output_attentions=False,
output_hidden_states=False)
optimizer = AdamW(model.parameters(),
lr = 4e-5,
eps = 1e-6
)
if run_on == 'cuda':
model.cuda()
# Define number of epochs
epochs = 3
total_steps = len(train_dataloader) * epochs
# Create the learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)Definimos una función para formatear el tiempo y otra para calcular la exactitud.
#fuction to format time
def format_time(elapsed):
elapsed_rounded = int(round((elapsed)))
return str(datetime.timedelta(seconds=elapsed_rounded))
#function to compute accuracy
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)Por último definimos la función que se encargará de entrenar el modelo y también de entregar los resultados en el set de validación.
#function to train the model
def training(n_epochs, training_dataloader,
validation_dataloader):
# ========================================
# Training
# ========================================
print('======= Training =======')
for epoch_i in range(0,n_epochs):
# Perform one full pass over the training set
print("")
print('======= Epoch {:} / {:} ======='.format(
epoch_i + 1, epochs))
# Measure how long the training epoch takes.
t0 = time.time()
# Reset the total loss for this epoch.
total_loss = 0
# Put the model into training mode.
model.train()
# For each batch of training data
for step, batch in enumerate(training_dataloader):
batch_loss = 0
# Unpack this training batch from dataloader
# [0]: input ids, [1]: attention masks,
# [2]: labels
b_input_ids,b_input_mask, b_labels = tuple(
t.to(device) for t in batch)
# Clear any previously calculated gradients
model.zero_grad()
# Perform a forward pass
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# pull loss value out of the output tuple
loss = outputs[0]
batch_loss += loss.item()
total_loss += loss.item()
# Perform a backward pass
loss.backward()
# Clip the norm of the gradients to 1.0.
torch.nn.utils.clip_grad_norm_(model.parameters(),
1.0)
# Update parameters
# ¿take a step using the computed gradient
optimizer.step()
scheduler.step()
print('batch loss: {0} | avg loss: {1}'.format(
batch_loss, total_loss/(step+1)))
# Calculate the average loss over the training data.
avg_train_loss = total_loss / len(train_dataloader)
print("")
print(" Average training loss: {0:.2f}".
format(avg_train_loss))
print(" Training epoch took: {:}".format(
format_time(time.time() - t0)))
# ========================================
# Validation
# ========================================
# After the completion of each training epoch,
# measure accuracy on the validation set.
print("")
print("======= Validation =======")
t0 = time.time()
# Put the model in evaluation mode
model.eval()
# Tracking variables
eval_loss, eval_accuracy = 0, 0
all_logits = []
all_labels = []
# Evaluate data for one epoch
for step, batch in enumerate(validation_dataloader):
# Add batch to device
# Unpack this training batch from our dataloader.
# [0]: input ids, [1]: attention masks,
# [2]: labels
b_input_ids, b_input_mask, b_labels = tuple(
t.to(device) for t in batch)
# Model will not to compute gradients
with torch.no_grad():
# Forward pass
# This will return the logits
outputs = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
# The "logits" are the output values
# prior to applying an activation function
logits = outputs[0]
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
b_labels = b_labels.to('cpu').numpy()
# Save batch logits and labels
# We will use thoses in the confusion matrix
predict_labels = np.argmax(
logits, axis=1).flatten()
all_logits.extend(predict_labels.tolist())
all_labels.extend(b_labels.tolist())
# Calculate the accuracy for this batch
tmp_eval_accuracy = flat_accuracy(
logits, b_labels)
# Accumulate the total accuracy.
eval_accuracy += tmp_eval_accuracy
# Report the final accuracy for this validation run.
print(" Accuracy: {0:.2f}".
format(eval_accuracy / (step+1)))
print(" Validation took: {:}".format(
format_time(time.time() - t0)))
#print the confusion matrix"
conf = confusion_matrix(
all_labels, all_logits, normalize='true')
print(conf)
print("")
print("Training complete")
#call function to train the model
training(epochs, train_dataloader, val_dataloader)
El modelo que da mejores resultados es con 3 epochs y un batch de 32. Este nos da una exactitud de 0.83 y la siguiente matriz de confusión:
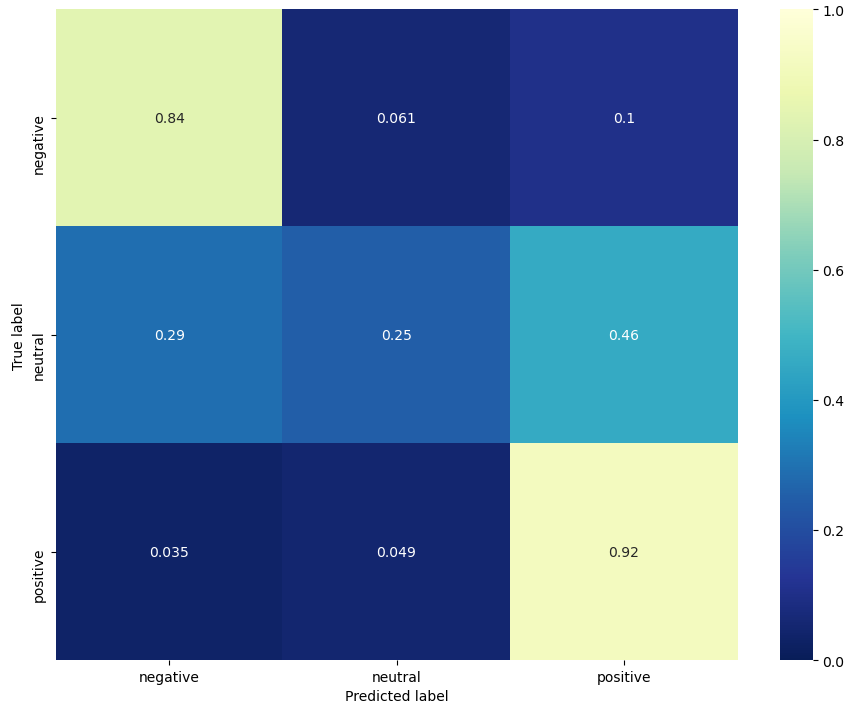
Conclusiones
A pesar de que con BERT obtenemos mejores resultados que en nuestro modelo de referencia, de igual manera tiene problemas en clasificar las opiniones del tipo neutral. Esto puede ser porque nuestro dataset no presenta muchos casos de esta categoría y también porque es una tarea difícil (incluso para una persona) y donde la capacidad de detectar contexto de BERT no parece ayudar demasiado . Por ejemplo, de estas opiniones ¿cuáles uno calificaría como neutral? ( es solo una):
| n° | Opiniones |
|---|---|
| 1 | Funciona bien ,pero su opción de chat funciona de forma errática |
| 2 | Buena app pero deberían agregar una categoría de pesca, caza y outdoors. |
| 3 | Me encanta Yapo y lo ocupo a diario, pero a nivel de Aplicación le falta harto para lograr ser más amigable. |
| 4 | Buena aplicación solo que debería notificar cuando el aviso no es publicado después de ser revisado. |
La respuesta es la numero 3. Difícil, ¿no?